Why Unicode Is Not My Favorite
I think I’ve had this conversation three times this week, so I’m going to record it while it’s still fresh.
The Unicode standard is a standard for a group of encodings aimed to capture all written characters, roughly. The goal of this operation is to unify all computer character encodings previously in use and replace them with one used everywhere: thus, unicode.
By “unicode”, most people intend the UTF-8 encoding. This is an eight-bit wide variable length encoding, which means that it uses groups of eight bits (i.e., a byte) of varying length to encode characters. For instance, ‘a’ takes one byte to represent, while ‘与’ tales two. We’ll see more of ‘与’ in a minute, don’t worry.
Problems?
-
Despite the name, there are several different ways to actually represent unicode “codepoints” (as they call them). In particular, Microsoft currently uses UTF-16, which is a sixteen-bit wide variable length encoding. Previously, they used UCS-2, which is the same as UTF-16 but fixed width (i.e., all characters are 16 bits wide, which is 2 bytes, hence the name). UCS-2 is a strict subset of UTF-16, so migration on their part was not impossible, and occurred after there were more codepoints in the unicode standard than could be represented in UCS-2.
-
Variable-width encodings are unisuitable for some applications. It is very useful to be able to seek arbitrarily into a string in many cases, and one cannot do this in UTF-8. To address the need for a fixed-width encoding (in some applications), there is also UCS-4 (or UTF-32). UCS-4 is identical to UCS-2 except that it is 4 bytes wide instead of 2. Because of the enormity of its size, it will be able to represent all of everything that could possibly be put into the unicode standard in the time between now and our deaths, many times. We will see more of UCS-4 in a moment.
-
There isn’t a clear understanding of how big anything is. Something of an outgrowth of the previous problem, to be sure, but not every codepoint is printable. Unicode, as a superset of ASCII, retains control characters; it also makes the problem worse by encoding display information as well, such as text direction. As a result, in order to know how much display space is required to print a unicode string, one has to parse the string.
-
Converting between unicode encodings is not easy. Of course going, for instance, from UCS-2 to UCS-16 is easy, but the conversion the other direction can just fail. Additionally, in order to convert anything to or from UTF-8, it’s easiest to just convert to UCS-4 because the characters aren’t clearly related otherwise.
-
Unicode is not tightly packed. As an encoding, UCS-2 and UCS-4 have substantially fewer characters than 2^16 and 2^32, respectively. (UCS-4 is limited to around 2^21.) This is a consequence of other properties of the encoding useful for variable width, such as being able to recover character boundaries in a stream. While this is novel, I don’t consider it useful and indeed know of no instances where it is used.
-
It fails its primary goal. First, look at this chart of UTF-8 adoption. It shows that UTF-8 has largely driven out other codings, with the exception of the JIS-variants. JIS is a method of encoding Japanese, so what’s up with that? Well, in an effort to keep this encoding small, the Unicode consortium decided to unify characters with common origin: the Han glyphs. The result is
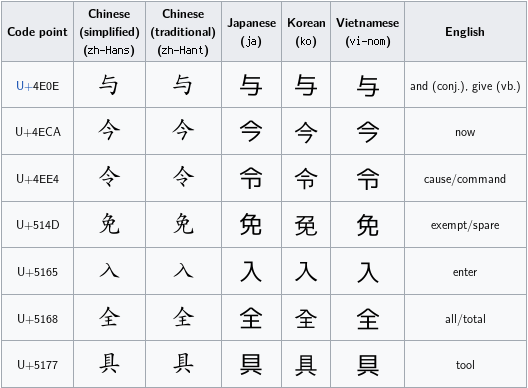 .
.
(This is a screenshot of this wikipedia article showing some of the problematic characters as a result of this decision, in my browser which doesn’t have particularly many fonts, by me, a non-speaker of all these languages. -
It’s too big. When the goal of keeping it small was abandoned, they brought in the kitchen sink. Since codepoints in the higher ranges are used (i.e., emoji), this means that the encoding isn’t even particularly compact for Latinate encoding anymore in common use. To make this maximally absurd, I was reading this last week as well.
{kind=link}
I actually don’t have a better closer than that last link. I can’t even parody that anymore.